Overview
Rockfish Hybrid Deployment Overview
Introduction
The Rockfish Data Workbench can be deployed and used as a SaaS application, deployed and installed fully on prem, or you can run the compute process on prem and leave the application up to us to run in our Hybrid deployment mode. In Hybrid mode your data doesn't need to leave your datacenter or cloud VPC. You will access the application at https://app.rockfish.ai, where you can configure, schedule, run, and manage your workflows and datasets. You will only need the ability to download a Docker image from our registry or have one loaded into your registry, a license, and some configuration templates filled out with the specifications for your deployment. The documentation will walk you through each step of the setup, and you can always reach out to our support team if you run into problems by emailing us at support@rockfish.ai
Getting started
Before you get started please take a quick look at the overviews for each sub-section of the installation guide. This will help to ensure you have access to the required components to deploy Rockfish. Each section will walk you through what you need installed or have access to. There is also a summary you can reference for a full list of requirements and links to external documentation. We suggest you to follow along with this document to get up and going, but each section will reference previous portions of the documentation where there are prerequiste steps.
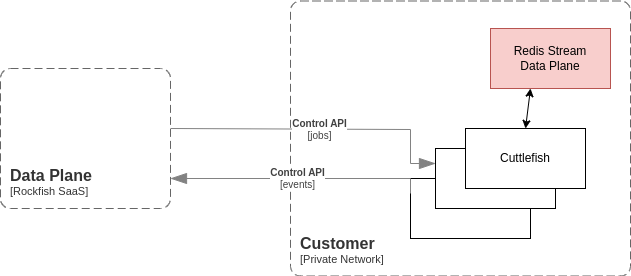
Deployment Infrastructure
In Hybrid deployment mode Rockfish Data hosts most of the services required, you only need to run our pipeline workers. You can find more details about Hybrid Deployment and diagrams. These workers perform our data ingest, pre and post processing, data encoding, training, generation, and data augmentation processes. Depending on your needs you will configure the appropriate number of workers for your workflows and assign them to the most suitable hardware. The hardware guide will help you select the setup that fits your data and our support team is happy to help you with specifics.
{kind=link}
Once you are set with the hardware, it is required that you deploy a docker image and start it on your virtual machines. Although the service can be deployed with Docker Compose you can take advantage of Docker orchestration frameworks features for scaling and process management. The installation instructions will cover Docker and Kubernetes. You will need to configure your containers to have the right API endpoints, authentication tokens, and any worker options that will help optimize your workflows. With the required workers nodes registered you should be able to open the web application or use our SDK to start connecting to your data sources and training your synthetic data models.
To get started head to the 3rd party resources page for details on the open source tools you will need and once you have those you are ready to start deploying the Rockfish Data Pipeline.